SQL to MongoDB Mapping: A Complete Information for Database Migration
Associated Articles: SQL to MongoDB Mapping: A Complete Information for Database Migration
Introduction
With nice pleasure, we’ll discover the intriguing subject associated to SQL to MongoDB Mapping: A Complete Information for Database Migration. Let’s weave fascinating info and supply recent views to the readers.
Desk of Content material
SQL to MongoDB Mapping: A Complete Information for Database Migration
![[NoSQL] MongoDB](https://kciter.so/images/2021-02-25-about-mongodb/mongodb-layer.jpg)
Migrating from a relational database like SQL to a NoSQL database like MongoDB requires a cautious understanding of the elemental variations between the 2 paradigms. This text supplies an in depth mapping chart and clarification to assist builders navigate this transition easily. Whereas a direct, one-to-one mapping is commonly not possible, understanding the core ideas and obtainable methods permits for environment friendly and efficient knowledge migration and utility restructuring.
Understanding the Elementary Variations:
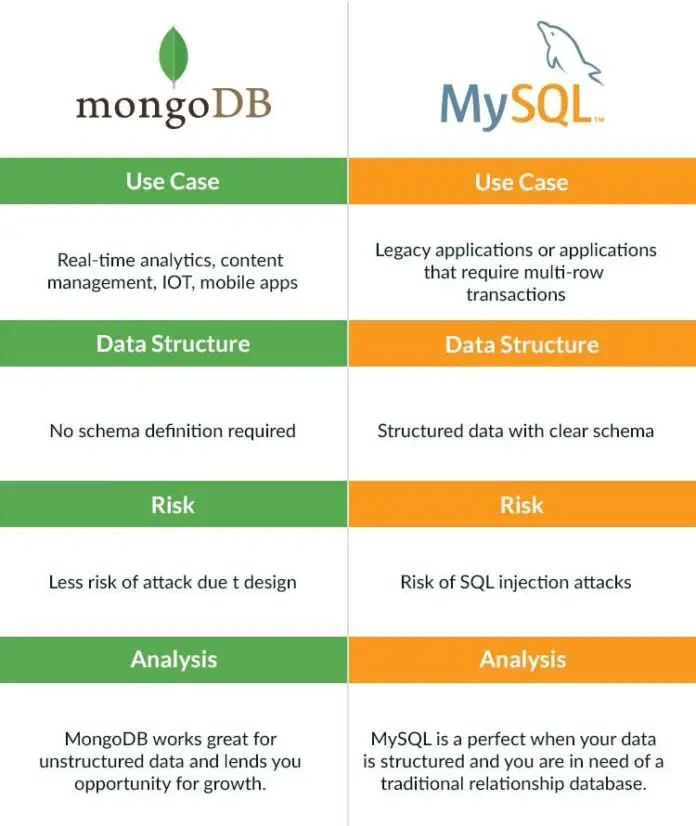
SQL databases, like MySQL, PostgreSQL, and SQL Server, are relational databases constructed on the idea of structured tables with rows and columns, implementing relationships via international keys and guaranteeing knowledge integrity via constraints. They excel in dealing with structured, predictable knowledge with well-defined relationships.
MongoDB, however, is a NoSQL, document-oriented database. Information is saved in versatile, JSON-like paperwork, permitting for schema flexibility and scalability. Relationships are dealt with otherwise, usually via embedded paperwork or references, and knowledge integrity depends on application-level logic somewhat than inflexible database constraints.
This inherent distinction necessitates a nuanced method to mapping SQL buildings to MongoDB equivalents. A easy column-to-field mapping is not enough; it requires contemplating knowledge modeling, question patterns, and utility logic.
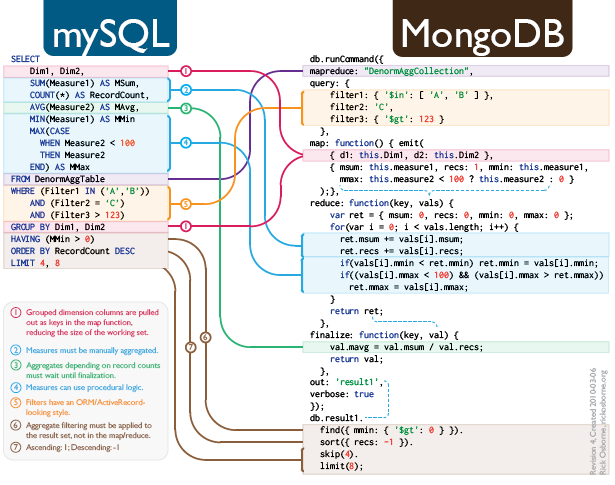
SQL to MongoDB Mapping Chart:
The next chart supplies a complete overview of the mapping methods, specializing in widespread SQL constructs and their MongoDB counterparts. Word that the optimum method usually depends upon the particular use case and knowledge traits.
| SQL Assemble | MongoDB Equal | Clarification | Instance |
|---|---|---|---|
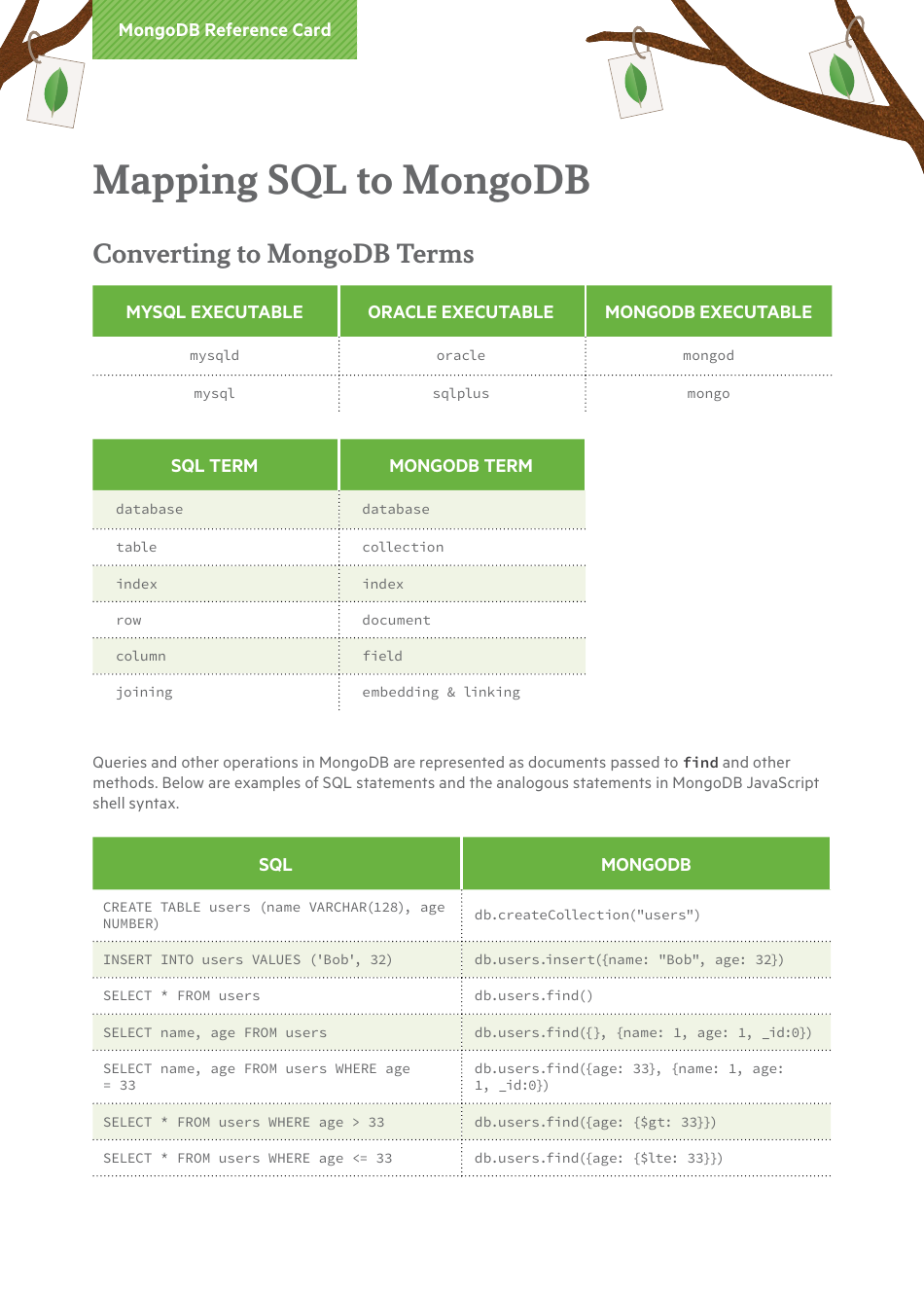
| Tables | Collections | Tables in SQL translate to collections in MongoDB. Collections are primarily units of paperwork. |
SQL: customers desk -> MongoDB: customers assortment
|
| Rows | Paperwork | Every row in a SQL desk turns into a doc in a MongoDB assortment. |
SQL: person with ID 1 -> MongoDB: "_id": 1, "title": "John", ...
|
| Columns | Fields | Columns change into fields inside a doc. Information sorts want cautious consideration. |
SQL: person.title -> MongoDB: "title": "John"
|
| Information Sorts | Related however with nuances | Most SQL knowledge sorts have MongoDB equivalents (e.g., INT -> Quantity, VARCHAR -> String, DATE -> Date). Nonetheless, nuances exist; as an example, MongoDB would not implement strict schema. | See detailed clarification under. |
| Major Key |
_id area (usually ObjectId) |
MongoDB mechanically assigns a singular _id area to every doc. Whilst you can specify your individual _id, utilizing ObjectId is mostly really helpful for its efficiency advantages. |
SQL: customers.id (main key) -> MongoDB: "_id": ObjectId(...)
|
| Overseas Keys | Embedded Paperwork, References, or Joins | Dealing with relationships requires cautious consideration. Embedding paperwork inside a father or mother doc works properly for one-to-many relationships with a small variety of baby paperwork. References (utilizing _id) are higher for bigger datasets or many-to-many relationships. MongoDB would not have direct be a part of performance; utility logic handles relationship traversal. |
See detailed clarification under. |
| Indexes | Indexes | Each SQL and MongoDB help indexes to enhance question efficiency. Indexing methods want adaptation to the doc construction. |
SQL: index on customers.title -> MongoDB: index on customers assortment's title area
|
| Relationships (One-to-many) | Embedded Paperwork or References | Embedded paperwork are environment friendly for small datasets. References are higher for bigger datasets to keep away from doc dimension bloat. | See detailed clarification under. |
| Relationships (Many-to-many) | References and separate collections | Requires a separate assortment to symbolize the connection, with references to paperwork within the associated collections. | See detailed clarification under. |
| Transactions | Restricted Transaction Assist | MongoDB provides restricted transaction help in comparison with SQL databases. Utility-level logic usually must deal with knowledge consistency. | Requires cautious design to make sure knowledge integrity. |
| Constraints (e.g., NOT NULL, UNIQUE) | Utility-Degree Validation | Database constraints aren’t immediately enforced in MongoDB; validation usually happens inside the utility logic. | Requires cautious design and implementation. |
| Saved Procedures | Aggregation Pipelines, Server-Facet JavaScript | MongoDB makes use of aggregation pipelines and server-side JavaScript for complicated knowledge processing, offering related performance to saved procedures however with a special method. | See detailed clarification under. |
Detailed Clarification of Key Mapping Methods:
Information Sorts:
-
Numbers: SQL’s
INT,BIGINT,FLOAT,DOUBLEmap to MongoDB’sQuantity. -
Strings: SQL’s
VARCHAR,CHAR,TEXTmap to MongoDB’sString. -
Dates: SQL’s
DATE,DATETIME,TIMESTAMPmap to MongoDB’sDate. -
Booleans: SQL’s
BOOLEANmaps to MongoDB’sBoolean. - Arrays: SQL would not have a direct equal, however MongoDB’s arrays are extremely helpful for representing lists or collections inside a doc.
-
Binary Information: SQL’s
BLOBmaps to MongoDB’sBinData.
Dealing with Relationships:
1. One-to-many relationships:
-
Embedded Paperwork: Very best for small datasets. The kid paperwork are embedded immediately inside the father or mother doc. This improves question efficiency by decreasing the necessity for joins. Nonetheless, it might probably result in doc dimension bloat if the variety of baby paperwork is massive.
-
References: Makes use of the
_idof the kid doc as a reference inside the father or mother doc. This avoids doc dimension bloat however requires separate queries to retrieve the kid paperwork.
2. Many-to-many relationships:
This requires a separate assortment to symbolize the connection. Every doc on this assortment comprises references (utilizing _id) to paperwork in each associated collections.
Saved Procedures and Complicated Logic:
MongoDB would not have saved procedures in the identical method as SQL. As an alternative, complicated knowledge processing is usually dealt with utilizing:
-
Aggregation Pipelines: A strong framework for performing complicated knowledge transformations and aggregations. They provide a declarative approach to specify knowledge processing levels.
-
Server-Facet JavaScript: Permits for extra versatile and customised knowledge processing, however requires cautious consideration of efficiency implications.
Instance State of affairs: Migrating a Consumer-Order Database
Let’s contemplate a easy SQL database with two tables: customers and orders. The customers desk has id (main key), title, and electronic mail. The orders desk has id (main key), user_id (international key referencing customers.id), order_date, and total_amount.
SQL Schema:
CREATE TABLE customers (
id INT PRIMARY KEY,
title VARCHAR(255),
electronic mail VARCHAR(255)
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT,
order_date DATE,
total_amount DECIMAL(10, 2),
FOREIGN KEY (user_id) REFERENCES customers(id)
);MongoDB Schema (utilizing embedded paperwork):
"_id": ObjectId("..."),
"title": "John Doe",
"electronic mail": "[email protected]",
"orders": [
"orderId": 1,
"orderDate": ISODate("2024-03-08T12:00:00Z"),
"totalAmount": 100.00
,
"orderId": 2,
"orderDate": ISODate("2024-03-15T15:30:00Z"),
"totalAmount": 50.50
]
MongoDB Schema (utilizing references):
// customers assortment
"_id": ObjectId("..."),
"title": "John Doe",
"electronic mail": "[email protected]"
// orders assortment
"_id": ObjectId("..."),
"userId": ObjectId("..."), // Reference to the person doc
"orderDate": ISODate("2024-03-08T12:00:00Z"),
"totalAmount": 100.00
The selection between embedded paperwork and references depends upon the anticipated variety of orders per person. For numerous orders, references are most well-liked to keep away from excessively massive paperwork.
Conclusion:
Migrating from SQL to MongoDB requires an intensive understanding of each database methods and a strategic method to knowledge modeling. This text supplies a foundational mapping chart and explanations to information builders via this course of. Do not forget that the optimum mapping technique relies upon closely on the particular utility necessities and knowledge traits. Cautious planning, thorough testing, and a phased migration method are essential for a profitable transition. Think about using migration instruments to automate elements of the method and decrease handbook effort. By understanding the core variations and adapting your knowledge mannequin accordingly, you’ll be able to leverage the scalability and adaptability of MongoDB whereas preserving the important performance of your utility.



Closure
Thus, we hope this text has offered helpful insights into SQL to MongoDB Mapping: A Complete Information for Database Migration. We thanks for taking the time to learn this text. See you in our subsequent article!